数据成果
数据获取
在大数据及人工智能背景下,燕山大学计算机系知识工程组实验室(KEG),利用机器学习及自然语言处理前沿技术,自主研发基于深度学习算法技术的自动化互联网数据获取技术和通用抽取引擎技术,自主创建规范的标准采集流程和评估指标,并获得多项发明专利,在此基础上研发数据采集系统:分布式互联网科技大数据采集&集成软件系统(PES++),它是一个集互联网论文、期刊、PDF抓取,数据集成和服务支持于一体的分布式、自动化、可配置的面向互联网学术信息抓取及管理平台,以支撑大数据智能系统获得海量、准确高效和可控易用的数据的需求。目前数据成果包括采集并集成科技新闻900万、科技活动(CFP)10万、专家信息3千万、Google Citation3千万、论文信息1.007亿条(其中高精度数据5.5千万条),累积抓取并检索数据量为2000GB。已合作用户包括:
1)北京搜狗公司(面向微博空间兴趣点数据采集)
2)北京紫絮公司(微信数据获取及挖掘分析)
3)清华大学KEG(李涓子教授,互联网新闻采集,百度百科数据采集)
4)南京知乎公司(互联网学术论文数据获取)
5)燕大材料国重实验室(材料性能数据采集)
6)北京智谱AI公司(科技论文大数据、人才数据及通用知识数据等)
数据标注
目前已搭建面向人工智能大模型垂直域应用开发的数据标注团队,团队包括博士人员4名,硕士人员30名、本科人员40名。专业涵盖人工智能、电子信息、金融等方向。人员和专业优势可支撑完成高难度、高质量数据处理任务。实验室自主设计数据标注流程。
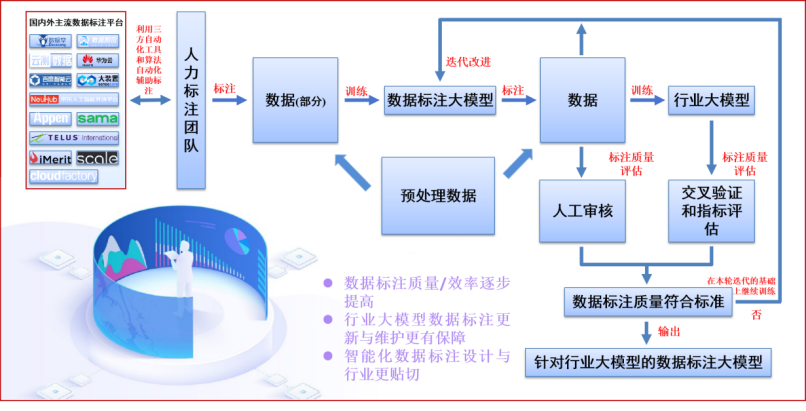
已为燕山大学继续教育学院标注问答数据1万条用于搭建问答大模型;标注高质量量化金融数据5万条,亚马逊科学研究英文问答数据1万条(后续更多)。为清华大学提供面向学术知识服务数据采集工具研发及最具影响力学者数据人工标注服务,为北京智谱AI公司提供交通运单大数据标注服务,并开发自主知识产权的数据标注系统。